

How is the MLOps culture developed?
Nowadays, data scientists and Machine Learning engineers face many commonly recognized pain points in the process of developing and serving high-performing ML models in operations. Some of the typical challenges are:
- Managing and keeping track of complex details, such as data, model architectures, hyperparameters, and experiments.
- Pinpointing the best-performing model that balances
- Controlling the experiment space and collaborating, etc.
The gap between ML development and ML operation is rooted deeply and has been a challenge for a while. In the real-world business environment, only a small fraction of the ML system is composed of the ML code. As shown in the following chart, many required surrounding elements are vast and complex. Thus, to make an ML system function efficiently and productively, data engineers have to deal with other elements, such as data validation, feature engineering, model analysis, metadata management, etc.

Thus, the MLOps concept was developed to adapt to the industrial long-term and fast-growing needs of serving a highly-performing ML system. Applying DevOps principles to ML systems (MLOps) will hinge the ML engineering stages and help develop and operate complex systems more effectively. Practicing MLOps aims to advocate for automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment, and infrastructure management.
What are the key phases in MLOps?
As MLOps is getting more and more popular within the industry, an ever-growing set of standards is built to better unify ML system development (Dev) and ML system operation (Ops). According to Google, there are 3 levels of automation to define the ML process maturity.
- Level 0: Manual process, no MLOps
Many teams at the fundamental level of maturity, or level 0, have data scientists and machine learning researchers who can construct cutting-edge models, but their method for building and deploying ML models is essentially manual.
- Level 1: ML Pipeline Automation
MLOps level 1 aims to perform continuous model training by automating the ML pipeline. This allows you to give the model prediction service continuously. To automate the process of retraining models in production using new data, you must include automated data and model validation processes in the pipeline, as well as pipeline triggers and metadata management.
- Level 2: CI/CO Pipeline Automation
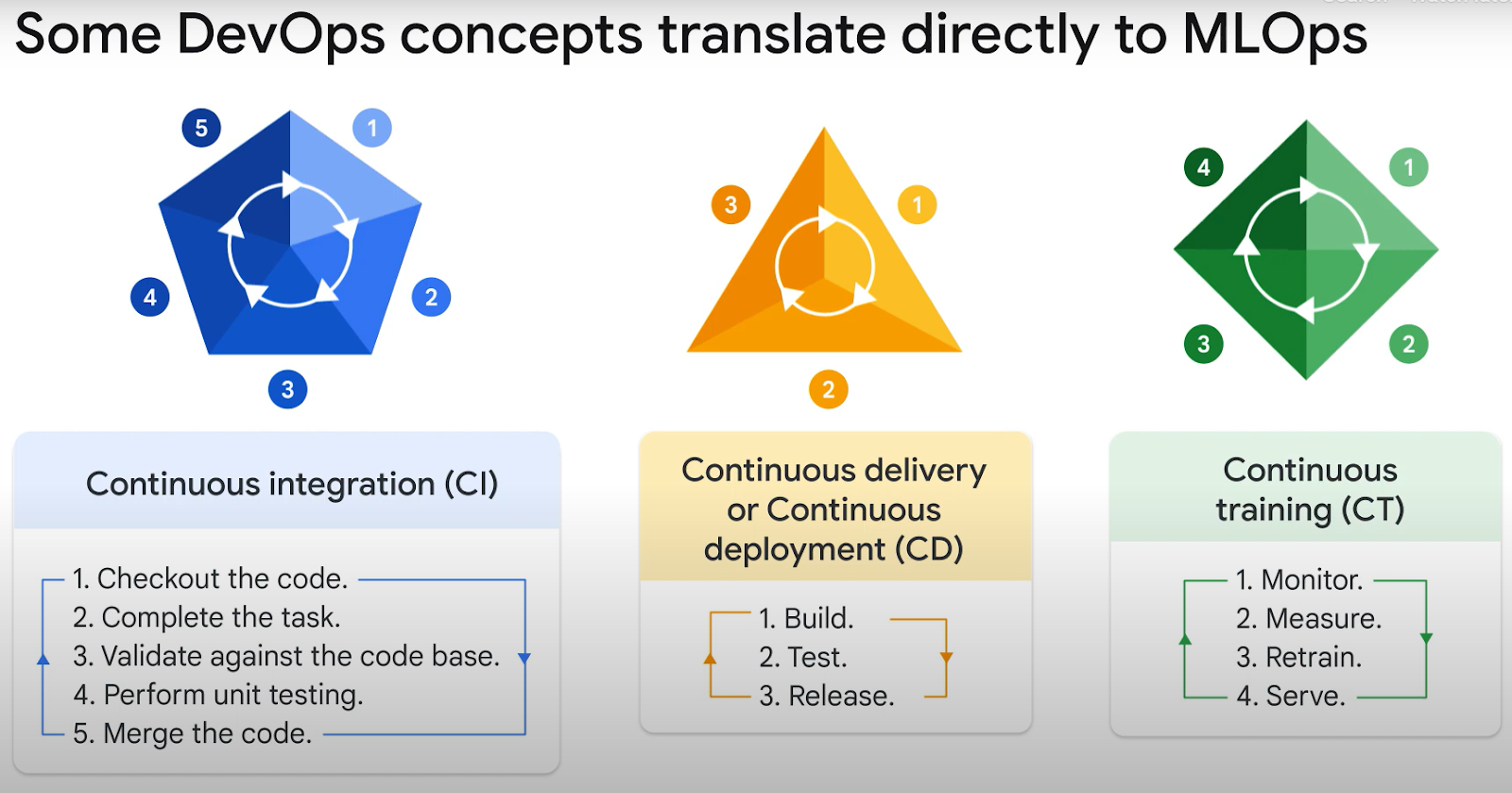
MLOps level 2 can be determined by Continuous Integration/Continuous Deployment, or CI/CD, pipeline automation because a robust automated CI/CD system is required for a rapid and reliable update of production pipelines. This automated CI/CD solution enables ML practitioners to quickly explore novel ideas in the areas of feature engineering, model design, and hyperparameters.
Notably, you might already be familiar with the CI/CO in DevOps, but in MLOps, the concepts are slightly different.
- Continuous Integration (CI) is no longer limited to testing and validating code and components, but also data, data schemas, and models.
- Continuous Deployment (CD) refers to a system (an ML training pipeline) that should automatically deploy another service (model prediction service) or roll back modifications from a model.
- Continuous Testing (CT) is a new, ML-specific characteristic concerned with automatically retraining and serving models.
How are the MLOps elements unified within the GCP ecosystem?
MLOps seeks to provide an end-to-end machine learning development process for designing, building, and managing reproducible, testable, and evolvable ML-powered software via Machine Learning Model Operationalization Management. Following are the MLOps components that GCP products can unify:
- A CI pipeline: builds, tests, and packages the components of the ML pipeline.
- A CD pipeline: deploys the ML pipeline to appropriate environments, like staging or production environments.
- ML pipeline: prepares training data and trains ML models. It includes the following steps:
- Data extraction is the process of obtaining training datasets from preset data sources.
- Data validation detects errors in the data structure and data value distribution.
- Data preparation involves data cleansing, data transformation, and feature engineering.
- Model training produces trained models using training data and other ML approaches.
- Model evaluation evaluates the trained model's performance on the test dataset (from the previous model training stage).
- Model validation determines if the trained model passes the predicted performance threshold for deployment.
- ML pipeline triggers: events published to Pub/Sub that trigger the ML pipeline for continuous training.
The ML system components must run at scale on a stable and dependable platform in a production setting. The chart below detailedly introduces how each stage of the ML pipeline is executed utilizing a managed service on Google Cloud, ensuring large-scale agility, reliability, and reproductivity.
|
Step |
Google Cloud service |
|
Data extraction and validation |
|
|
Data transformation |
|
|
Model training and tuning |
|
|
Model evaluation and validation |
|
|
Model serving for predictions |
|
|
Model Storage |
Why is MLOps important and to whom it will be valuable?
MLOps provides the following benefits by combining ML engineering with ML system development:
- Shorter development cycles: with a more integrated development and operation process, the model deployment will be smoother and streamlined. Data scientists will adjust and retrain the models based on closely monitoring the baseline performance and trends of the model operation. Without switching between several ML platforms between the development and operations integration, MLOps culture will shorten the ML process and save data scientists much time when merging the gaps between the pipelines.
- Enhanced team cooperation: Data scientists will work more closely in the same pipeline and platform. Since MLOps encourages an open, honest, and inclusive atmosphere in which team members may freely share their ideas and thoughts, the MLOps team fosters an environment that encourages collaboration, growth, and innovation.
- Improved ML system performance and stability. Older ML models tend to decay in performance, thus MLOps promotes a continuous model monitoring process to identify the performance metrics and optimize a strategy for model serving before reaching production.
Overall, the MLOps platform provides a collaborative environment for data scientists and software engineers that enables iterative data exploration, streamlines collaborative capabilities for model experiment tracking, as well as optimizes controlled model transitioning, deployment, and monitoring. In conclusion, with the MLOps strategies, the machine learning lifecycle's operational and synchronization parts will be automated and integrated seamlessly. MLOps-enabled model creation and deployment implies faster time to market and lower operating expenses and will enable managers and developers to make more agile and strategic decisions. MLOps is a hot topic that’s continuously and rapidly developing, with new tools and processes adapting all the time. If you get on the MLOps train now, you will get a huge competitive advantage.
References:
https://www.cloudskillsboost.google/course_sessions/5831067/video/392201
https://cloud.google.com/architecture/mlops-intelligent-products-essentials
https://www.linkedin.com/pulse/team-building-collaboration-mlops-strategies-creating-monika-obrocka/
Ready to grow your company to the next level?
Contact Napkyn to discuss the tailored solutions we can implement for your team.

